Understanding Crawling: 13 Techniques and Top Tools
It is increasingly essential for search engines to find, organize, and rank web pages and take the lead in the competitive industry. Crawling speeds up this process efficiently, It is the backbone of how search engines index and rank content. Googlebot, which is Google’s web crawler, processes over 40 billion pages daily.
Hence, without effective crawling, search engines like Google, Bing, and others would struggle to display the most relevant results to users. This article covers the basics of crawling, its importance, various strategies to enhance efficiency and highlights the top tools.
What Do You Understand By Crawling?
Web crawling is a technique for extracting data from websites. Search engine bots (spiders or crawlers) visit and navigate web pages for web scraping, search engine indexing, and data mining.
When a search engine wants to update or expand its index, it sends out these bots to discover new pages, follow links, and gather content. Crawling ensures that your web pages appear in search engine results. Hence, your content needs to show up in search results, to be visible to search engines.
How Does Crawling Work, And Why Do You Need It?
Crawling includes discovering and accessing pages on the internet. These bots use links on one page to move to the next, systematically following a set of rules to find and read the content of each page.
The ultimate goal of crawling is to collect the data required for indexing, so the pages can be included in the search engine’s database. This allows you to discover new content on the web pages and make it appear in search results when relevant queries are made, making your site noticeable.
Without crawling, your website would not be indexed, making it invisible to search engines and users. Ultimately, they wouldn’t rank for relevant keywords, severely limiting traffic and visibility.
Crawling VS. Indexing
| Aspect | Crawling | Indexing |
| Definition | Crawling refers to discovering and retrieving web pages from the internet. | Indexing is the process of storing and organizing the content found during crawling. |
| Purpose | The main purpose is to find new and updated pages on the web. | The purpose is to store and organize the discovered content to display it for relevant queries. |
| Example | A crawler visits a page, extracts the links, and follows them. | The content on the page is stored and categorized for easy retrieval in future searches. |
What Is Crawling Budget?
| Aspect | Crawl Budget |
| Definition | Crawl budget refers to the number of pages or requests that Googlebot will crawl on a website during a given period. |
| Factors | The crawl budget is influenced by factors such as website size, popularity, content quality, update frequency, and site speed. |
| Importance for SEO | A limited crawl budget means fewer pages will be indexed, potentially leading to lower rankings for the website. |
13 Techniques To Improve Crawling
Here are some strategies that can help to improve your SEO performance so that search engines crawl your website efficiently:
1. Website speed

Website speed plays a crucial role in crawling efficiency. Slow-loading pages can result in search engine bots abandoning the crawl before it completes. Whereas, a faster server response time allows bots to crawl more pages in less time, ensuring they index more of your website.
2. Update Content
Not all content on your website is valuable for search engines. Low-quality or duplicate content, thin content, and pages with little relevance to your target audience can waste the crawl budget.
Identify, remove and update these pages to ensure that search engines focus efforts on more valuable content. Websites that prefer to keep updated content are likely to be frequently crawled
3. Train Googlebot What Not To Crawl
Using the robots.txt file, you can direct search engine bots about which pages should not be crawled. For example, administrative pages, user accounts, and duplicate content that provide no SEO value can be blocked. Properly configuring your robots.txt file prevents crawlers from wasting time on non-essential pages.
4. Use XML Sitemaps

XML sitemaps help search engines locate all of the pages on your website quickly. XML sitemap through Google Search Console makes it easier for crawlers to find and index your site’s most important pages and significantly enhances visibility and organic traffic. Thus, It’s crucial to ensure the sitemap is up-to-date and accurately reflects your site’s structure.
5. Fix Orphan pages
Orphan pages are web pages that are not linked to any other page on your website. Since search engines rely on links to discover pages, orphan pages may go unnoticed. Ensure that all important pages are interlinked properly and accessible through your site’s navigation or internal linking strategy.
6. Earn high-quality links
Both external and internal links are vital for crawling. High-quality links help crawlers discover new pages, and strong internal linking ensures that crawlers can easily navigate your site and boost authority. Ensure that all internal links are working and point to relevant pages.
7. Canonicalization
Canonicalization tells search engines which version of a page should be considered the authoritative one. This is especially important for pages with similar or duplicate content. By using canonical tags, you can avoid having search engines crawl and index multiple versions of the same page.
8. Robots.txt File
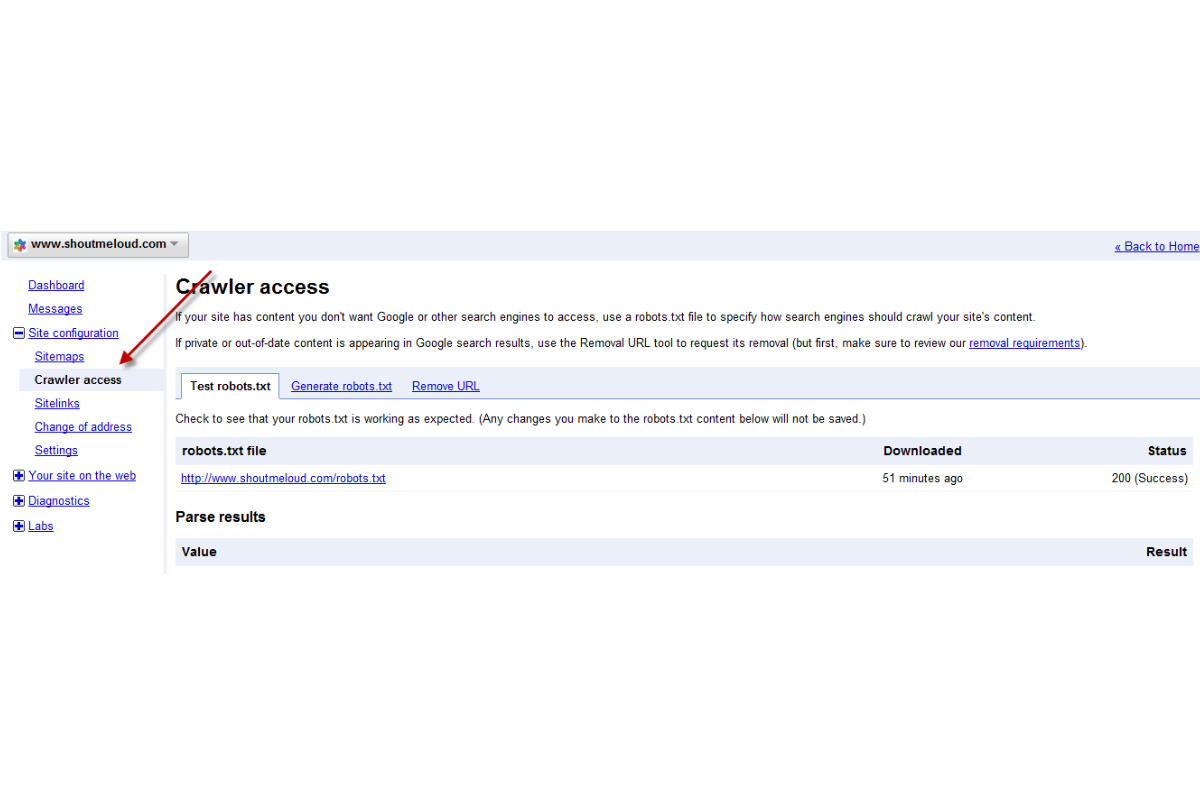
A well-optimized robots.txt file is essential for directing search engines on what to crawl and what to avoid. For example, you might block non-content pages or pages with parameters that could result in duplicate content. Fine-tuning this file can save valuable crawl resources.
9. Organize URL Structure
Maintain a clean and organized URL structure for effective crawling. URLs should be easy for both users and crawlers to understand. Avoid using excessively long URLs or ones with unnecessary parameters that can confuse crawlers.
Instead, use descriptive, concise URLs with hyphens separating words. Regularly check and alter your URL structure to match up with the changes in the structure and content of your website.
10. Fix Major Errors
Identify and fix crawling errors, such as 404 errors (page not found), broken links, or server errors to keep your website healthy. Google Search Console is a great tool for spotting these issues, and regular audits can help ensure that your pages are accessible to crawlers.
11. Use videos and images
Include images and videos on your site to increase user engagement with your content. Ensure that bots can crawl these media by using proper alt text and titles for each image or video file. Additionally, use a sitemap for images and videos to help bots locate these files.
12. Avoid Using Duplicate Content
Duplicate content can confuse search engines, as they may not know which version of the content to index. According to a survey by SEMrush, around 50% of websites have some form of duplicate content.
It wastes the crawl budget and also dilutes the SEO value of pages, potentially harming search rankings. Copied or plagiarized content is not the hallmark of authenticity and reliability and might also lead to a Google penalty.
13. Fix Broken Links
Broken links annoy visitors and lower your website’s search engine rankings. Use internet tools to regularly check your website for broken links. You can update these links on your website by either deleting them or fixing the URLs to boost SEO and conversions.
5 Top Tools To Improve Crawling
Several tools are available to help you monitor and improve your website’s crawling performance.
1. Screaming Frog: Screaming Frog is a popular website crawler that helps you analyze your site’s structure and identify crawl issues. It provides detailed reports on broken links, duplicate content, and much more.
2. Scrapy: Scrapy is a Python-based open-source web crawling framework designed for developers. It allows you to extract data from websites and customize your crawling strategies.
3. BeautifulSoup: This is another Python library used for web scraping. While it isn’t a dedicated crawling tool, it helps developers parse HTML and XML documents, making it easier to extract information from websites.
4. Selenium: This web testing tool can also be used for web scraping. It allows you to automate browser interactions, including loading pages and interacting with dynamic content.
5. Google Search Console: Google Search Console is an essential tool for webmasters to monitor how Googlebot crawls and indexes their site. It provides information about crawl errors, page performance, and indexing
5 Common Crawling Issues You Should Avoid
Ensuring your website is crawled effectively requires you to avoid certain pitfalls:
1. Crawling Errors: Errors like 404 or server errors can prevent crawlers from accessing important pages. Fix these errors immediately to avoid wasting the crawl budget.
2. Low-quality backlinks Leading to Dead Pages: Backlinks from low-quality or broken pages can redirect bots to dead ends. Ensure that all backlinks are functional and lead to relevant content.
3. Crawlers Restricted by IP Block: IP blocking or geographical restrictions can prevent crawlers from accessing your site.
4. Blocked International Pages: If you have international versions of your site, ensure they are accessible to crawlers, especially for regions with specific geo-targeting rules.
5. Crawl Traps: Crawl traps occur when a crawler gets stuck in an infinite loop or repeatedly visits the same pages. Ensure that your site structure prevents these traps from happening.
Conclusion
Crawling is an important process that powers search engines, helping them discover, index, and rank your content. Optimizing crawling is crucial for ensuring that search engines efficiently explore your site and deliver the best results to users.
Improve website speed, eliminate poor-quality content, use proper tools, and follow the right techniques, to boost your site’s crawling efficiency and chances of ranking higher in search engine results.
FAQs
Crawling is the process by which search engines use automated bots to discover and read pages on the web.
Crawling involves sending bots to a website, reading the content, and following links to discover new pages.
An example of crawling would be Googlebot visiting a webpage, reading its content, and then following any links on that page to explore other pages.